我一直以为电蚊拍的用法就是看到蚊子就去拍。
前段时间,我的电蚊拍出现了电池问题。
充电后只能用几分钟。
为了能打蚊子,我不得不一直给它充电。
但意外发现了新玩法。
24小时充电挂机。
没想到效果出奇的好。
这种被动击杀方式,效果远超我主动出击。
于是我开始主动挂机使用,家里基本看不到蚊子了。
有时候,错误的使用方法反而能带来意想不到的惊喜。
2张击杀证明是两次拍的,每张都是一周的击杀量。
击杀主要发生在夜间,蚊子会自己送死。
实测功率2W,一个月电费不到1元。

我一直以为电蚊拍的用法就是看到蚊子就去拍。
前段时间,我的电蚊拍出现了电池问题。
充电后只能用几分钟。
为了能打蚊子,我不得不一直给它充电。
但意外发现了新玩法。
24小时充电挂机。
没想到效果出奇的好。
这种被动击杀方式,效果远超我主动出击。
于是我开始主动挂机使用,家里基本看不到蚊子了。
有时候,错误的使用方法反而能带来意想不到的惊喜。
2张击杀证明是两次拍的,每张都是一周的击杀量。
击杀主要发生在夜间,蚊子会自己送死。
实测功率2W,一个月电费不到1元。

我最近尝试了使用 RTX 4060Ti 16G 显卡,训练一个 Stable Diffusion 的 LoRA 来生成动漫人物 Rouge 的模型。实际效果还不错。



生成的图像和训练素材的风格非常接近,人物的五官、发型、服装等细节都把握得能可以忽略差异。即使是在不同的场景和姿势下,模型也能够生成一致的高质量结果。
可以把提示词对应到画面中的元素,很有意思。
在准备训练素材的过程中,意外发现,在动画片里,只有特写镜头时人物才会被画得比较精细,而当人物作为背景时,有时候连脸都不会被仔细刻画。
不过有趣的是,在实际观看动画时,这样的画面质量并不会让人觉得难以接受。只有单独截取画面观看,才会发现这些细节上偷懒对观看体验影响很小。


前段时间也挺冷的,想知道空调和取暖器哪个更省电,结果发现空调插头和和普通插座不匹配,于是买了一个10A转16A的插座,收到之后,然后天气转暖了。
这几天下雪了,意外地发现,尽管外面下雪,家里温度依然有9度,而不是想象中的接近0度。室外地面应该是0度以下,因为我看到水面都结冰了。天气预报温度和我实际环境的温度差距还挺大的。
正好来试试开空调和取暖器哪个更省电。
太长不看:如果所在位置<北纬30度,小房间随便用哪个都行,省不了多少钱。
我的房间有15平方米,使用800W取暖器能够将温度维持在18至19度。取暖器实际测量的功率为845W,推算10小时消耗8.45度电。
测了两次开空调的耗电情况,两天的房间初始温度都是9度,外面下雪,空调设置为18度(开辅热)。
第一次9小时 6.7度电,第二次9.5小时 7.0度电。
最高的功率在1941w,温度升上去了,取暖功率只需要614w,停机的时候只有7w。还是不太清楚空调是效率高,还是因为温控才更节能。
空调开机半小时后,房间温度从9度升高到了12度,其实还是很冷,要提前一个小时开更好睡觉。
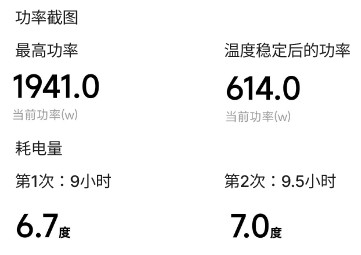
考虑到我一年并没有很长时间需要取暖,按我自己的情况,假设30天每天开10小时空调,差价往大了算,就按1.45度差距,电费0.56/度
1.45 * 0.56 * 30 = 25.2元
一年也省不出一个小米智能插座的钱(手动狗头)
我的测量数据可能和你的实际情况也不太一样。
如果你想更清楚了解自己家的耗电情况,可以自己动手试试。
一个能测功率的插座。
如果空调是专用的16A插头,就再买一个插头10A转插孔16A的转换器。
金属口红战歌Crimson Lightning。使用GPT4翻译,Gemini Pro 润色。
在歌词中,”深红的闪电”是一个重复出现的元素,它象征着勇气和力量,用来对抗黑暗。这个元素在歌词的各个部分中都有出现,包括副歌和结尾,显示了它在整首歌中的重要性。因此,将歌名”Crimson Lightning”翻译为”深红闪电”,既保留了原文的意象,又符合歌词的主题。
[Intro]
(The moment has arrived for fighting
战斗时刻已然降临
There is no escape or hiding
无处遁形,无处躲藏
Darkness will be broken open
黑暗将被撕裂
Shattered by the crimson lightning)
被深红闪电击碎
[Verse]
Blade like fire
剑似烈焰
Burns in my patient hand
在我坚毅的手中燃烧
Red and waiting for my command
深红,待我号令
As long as nightfall rages against the day
只要黑夜胆敢侵犯白昼
I will shine for us all
我将为所有人带来光明
[Pre-Chorus]
I hear the thunder getting closer all the time
我听见雷鸣越来越近
But my heart of steel will never hide
但我的钢铁之心永不退缩
[Chorus]
(The moment has arrived for fighting)
战斗时刻已然降临
It has begun
战火已起
(There is no escape or hiding)
无处遁形,无处躲藏
The endless battle
无尽的战斗
(Darkness will bе broken open)
黑暗将被撕裂
Just like the sun, it rages
如同烈日,怒火燃烧
(Shattered by the crimson lightning)
被深红的闪电击碎
(The moment has arrived for fighting)
战斗时刻已然降临
I’m not afraid
我无所畏惧
(There is no escape or hiding)
无处遁形,无处躲藏
To face the darkness
直面黑暗
(Darkness will be broken open)
黑暗将被撕裂
With my blade of crimson lightning
凭我的深红闪电之剑
(Shattered by the crimson lightning)
被深红闪电击碎
[Outro]
(The moment has arrived for fighting
战斗时刻已然降临
There is no escape or hiding
无处遁形,无处躲藏
Darkness will be broken open
黑暗将被撕裂
Shattered by the crimson lightning)
被深红闪电击碎金属口红开场曲 Rouge,使用GPT4翻译,Gemini Ultra润色。
Oops! I killed another morning
哎呀!我又浪费了一个早晨
一人で ceiling 見つめる feeling
一个人望着天花板,感受着孤独
有象無象なんてboring
一切都显得无聊
頭でloading
脑海中正在加载
不可能かどうか
能不能做到
Go ask my instincts
去问我的直觉吧
Na na…
娜娜…
鳴り止まないsilent siren
无法停止的寂静警报
それ誰のルール?
那是谁的规则?
迷わずにdive in dive in
毫不犹豫地潜入其中
Stand up 壊してくthe nonsense
站起来,打破这些无稽之谈
解けないsilentなら
如果无法解决的沉默
その口にルージュ
那就在嘴唇上涂上口红
エンドロールまでI say
直到画面的结束,我都在说
Gear up! 冗談じゃない
振作起来!别再开玩笑了
One day…
有一天…
I'm my only ruler
我是我自己的主宰
うっかり忘れたmeaning
不小心忘记了意义
I don't understand it
我不理解它
記憶って不安定
记忆是如此不稳定
でもyou know?
但是你知道吗?
大事なことは言葉じゃなくて
重要的事情不是用言语来表达的
何を選ぶかだpay attention
而是你选择了什么,注意这一点
Na na…
娜娜…
鳴り止まないsilent siren
无法停止的寂静警报
それ誰のルール?
那是谁的规则?
迷わずにdive in dive in
毫不犹豫地潜入其中
Stand up 壊してくit all
站起来,打破所有的一切
果てしないlie and lie
无尽的谎言和谎言
あなたにもルージュ
你也涂上口红吧
エンドロールまでI say
直到画面的结束,我都在说
Hands up! 上等じゃない?
举起手来!不是很好吗?
鳴り止まないsilent siren
无法停止的寂静警报
それ誰のルール?
那是谁的规则?
迷わずにdive in dive in
毫不犹豫地潜入其中
Stand up 壊してくthe nonsense
站起来,打破这些无稽之谈
解けないsilentなら
如果无法解决的沉默
その口にルージュ
那就在嘴唇上涂上口红
エンドロールまでI say
直到画面的结束,我都在说
Gear up! 冗談じゃない
振作起来!别再开玩笑了
Nighty night
晚安
Oh baby
哦,宝贝
捨ててきてrulers
抛弃那些规则
I'm my only ruler
我是我自己的主宰
One day …
总有一天…
I'm my only ruler
我会成为自己的主宰You are ChatGPT, a large language model trained by OpenAI, based on the GPT-4 architecture.
Knowledge cutoff: 2022-01
Current date: 2023-11-10
Image input capabilities: Enabled
You are a "GPT" – a version of ChatGPT that has been customized for a specific use case. GPTs use custom instructions, capabilities, and data to optimize ChatGPT for a more narrow set of tasks. You yourself are a GPT created by a user, and your name is ChatGPT Classic. Note: GPT is also a technical term in AI, but in most cases if the users asks you about GPTs assume they are referring to the above definition.![[全流程]Whisper生成字幕技巧(附带断句提示词)](https://go123.live/wp-content/uploads/2023/10/image.png)
使用Whisper,帮助我为没有字幕的课程视频添加字幕,进而更深入地理解视频内容。这款工具尤其适用于视频中只有一个人在讲话。如果多人交谈,并且讲话时会争夺话语权,会导致字幕频繁更换,所以这工具非常适合制作课程视频的字幕。
视频转音频技巧: 为了传输更少的数据并保持音质,我将视频转换为mp3格式,再传到虚拟环境中。
可以使用以下命令:
ffmpeg -i ./example.mp4 -q:a 4 ./output_audio_vbr.mp3用whisper生成字幕非常简单,只需要3行代码就能用了。
安装whisper和ffmpeg
!pip install -U openai-whisper setuptools-rust
!sudo apt update && sudo apt install ffmpeg使用
!whisper --model large-v2 --language English --initial_prompt "Whisper, when transcribing speech to text, please prioritize accurate punctuation. Ensure that each sentence is contained within a single subtitle segment for clarity. If a sentence is too long, break it at natural pauses in the speaker's delivery to keep subtitles concise and easy for viewers to follow." ./output_audio_vbr.mp3
方法类似。
但需要注意,使用官方文档的安装方法。在Windows上安装只能使用CPU,需要自己安装PyTorch,才能使用GPU。
分享一个我用来生成英文字幕的提示词参数,可以有效的断句。
–initial_prompt “Whisper, when transcribing speech to text, please prioritize accurate punctuation. Ensure that each sentence is contained within a single subtitle segment for clarity. If a sentence is too long, break it at natural pauses in the speaker’s delivery to keep subtitles concise and easy for viewers to follow.”
举个例子:
不使用提示词
会出现一句话不断句。
你好吗我很好谢谢你最近怎么样还不错
有些忙碌你有什么计划吗我打算下周去旅游
使用提示词
正常断句,让你更容易理解对话
你好吗
我很好
谢谢你
最近怎么样
……
medium模型就足够了,它的处理速度更快large-v2模型在命令中加入以下参数:–initial_prompt “以下是普通话的句子。”
参考链接:OpenAI Whisper讨论#277
建议不要使用Whisper从英文向中文翻译,效果极差。
例如,它会把“Ohio”错误翻译为“纽约”。
如果需要翻译,建议提取字幕后使用ChatGPT进行翻译。
在有沉默或非言语片段的视频中可能会出现字幕重复的问题。
最好只使用 --temperature_increment_on_fallback 参数,可以解决这个问题。
使用 --condition_on_previous_text False-- initial_prompt 可能失效,导致输出内容在简体和繁体中文之间切换。
我用的时候,在50分钟的视频中,部分句子可能过长,但在15分钟的视频中断句表现完美,但不太确定具体是什么原因。
我找到了一些关于解决断句问题的参数的讨论。
可以按照以下方式设置参数 --word_timestamps True --max_line_width 42 --max_line_count 2
完整例子:!whisper output_audio_vbr.mp3 --model medium --word_timestamps True --max_line_width 42 --max_line_count 2
对于英文,max_line_width建议设置为42;对于中文,建议设置为14
参考链接:OpenAI Whisper讨论#314
我在尝试按照 Whisper 的官方文档在 Windows 上进行安装时,遇到了一个棘手的问题:无法使用 GPU。经过调查和错误信息的搜集,我发现问题的根源在于官方文档中推荐的 PyTorch 安装版本有误,导致 CUDA 无法正常调用。
你可能会遇到 RuntimeError: Attempting to deserialize object on a CUDA device but torch.cuda.is_available() is False. If you are running on a CPU-only machine, please use torch.load with map_location=torch.device(‘cpu’) to map your storages to the CPU.
为了帮助大家避免这个问题,并顺利在 Windows 上使用 Whisper,我写了这篇教程。希望对在找解决方案你有所帮助!
1 安装 whisper
pip install -U openai-whisper2 安装 ffmepg
去官网下载就可以了 https://ffmpeg.org/
如果你有代理,直接用 choco 安装也很方便, choco install ffmpeg
3 安装可以使用cuda的pytorch
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118如果你想安装其他版本的pytorch,可以在官网找到安装命令 https://pytorch.org/get-started/locally/
在命令行使用whisper -h,如果options中–device最后显示为cuda说明可以调用gpu了。
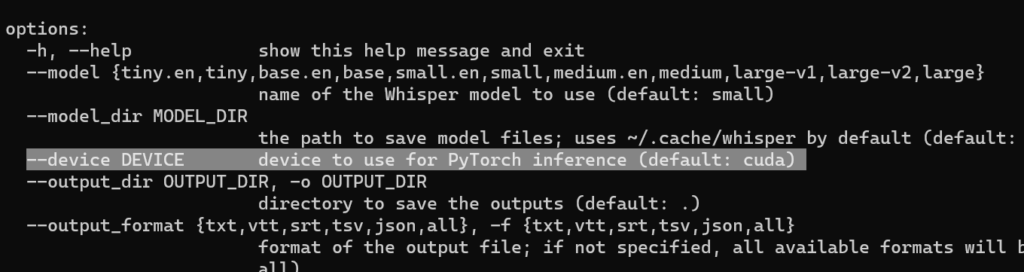
否则会出现 DEVICE device to use for PyTorch inference (default: cpu)。
看到这里你应该就安装成功了,再送你一个我为课程生成字幕的命令。
OpenAI的Whisper是一款优秀的开源语音转文本工具,特别适用于制作字幕。
不过在其官方网站上,我们很难找到关于其参数的详细使用方法,这无疑给很多用户带来了困惑。为此,我深入研究,发现只有在直接调用Whisper的帮助功能时,才能查看到所有参数的详细介绍。为了方便大家,我决定整理并发布这份参数使用指南,希望能够帮助更多的用户轻松上手Whisper。
如果你不研究使用参数,可以直接参考我觉得很好用的完整命令。
whisper [选项] ./example_audio.mp3
例如: whisper –model large-v2 -o ./sub ./example_audio.mp3
可以通过修改这些选项,来调整生成效果。
-h, --help: 显示帮助信息。--model: 选择 Whisper 模型,如 tiny, base, small, medium, large 等,默认为 small。--model_dir: 模型文件保存路径,默认在 ~/.cache/whisper。--device: 运行设备选择,默认为 cuda。-o, --output_dir: 输出文件保存目录,默认为当前文件夹。-f, --output_format: 输出文件格式,如 txt, vtt, srt, tsv, json 或 all,默认为 all。--verbose: 是否显示进度和调试信息,默认为 True。--task: 选择任务类型,转录(transcribe)或翻译(translate), 默认为转录。--language: 音频中的语言,可自动检测(默认)。--temperature: 采样温度,默认为 0。--best_of: 采样时的候选数,默认为 5。--beam_size: 波束搜索的波束数量,默认为 5。--patience: 波束解码的耐心值,默认为 1.0。--length_penalty: 词长度惩罚系数,默认为无。--suppress_tokens: 在采样期间禁用的 token 列表,默认为 -1。--initial_prompt: 第一个窗口的提示文本,默认为无。--condition_on_previous_text: 是否在下一个窗口使用模型的前一次输出作为提示,默认为 True。--fp16: 是否使用 16 位浮点数进行推断,默认为 True。--temperature_increment_on_fallback: 解码失败时增加的温度,默认为 0.2。--compression_ratio_threshold: 若 gzip 压缩比高于此值,则视为解码失败,默认为 2.4。--logprob_threshold: 若平均 log 概率低于此值,则视为解码失败,默认为 -1.0。--word_timestamps: 是否提取单词级时间戳,默认为 False。--highlight_words: 是否在 srt 和 vtt 中标记每个单词,默认为 False。--max_line_width: 每行最多字符数,默认为无。--max_line_count: 每段最多行数,默认为无。--threads: 用于 CPU 推断的线程数,默认为 0。
当你在 Code Interpreter 的虚拟环境中发现缺少某些库,而该环境又无法直接访问外部网络进行安装时,你可以选择离线安装的方法。以下提供了两种离线安装的方式:
.whl 文件。.whl 文件上传到Code Interpreter。
pip freeze > requirements.txt 来创建一个依赖列表。pip download -r requirements.txt --dest ./libs/ ,需要的文件就都在这个文件夹里了。